






Consumers not confident about data knowledge but eager to learn [Survey]
Key findings
- When scoring their own data-trafficking knowledge, respondents gave themselves less than 3 out of 5, on average.
- 42% of people felt very or extremely comfortable accepting user agreements without reading them first.
- 12% of consumers were extremely willing to trade their personal information for access to free online services.
- 58% of consumers were very or extremely interested in learning more about how their data is used.
If you want to use the internet in this day and age, the chances are you’ll have to give up your personal information to do so. Many of the most popular services make themselves free to use by harvesting and selling their users’ browsing data and contact information.
Unfortunately, many consumers who participate in this data-as-capital system are confused or unsure about how it works. Recent research has shown that it’s not common for individuals to have broad or deep data literacy. What’s more, users who mostly stick to social and entertainment media consistently have lower levels of data knowledge and awareness.
Unsupervised surveyed 1,012 internet users to study how people approach their personal online data privacy. How confident is the average American in their knowledge, and how willing are they to participate in the data-as-capital economy?
Self-confidence in terms of data knowledge
If you feel like your knowledge about the online data ecosystem is lacking, you’re not alone. Respondents to our survey generally had medium-to-low confidence in their knowledge of which companies traffic personal information and what they do with the data once they have it. The average rating for both these metrics was 2.9 and 2.8, respectively, on a scale from 1 to 5.
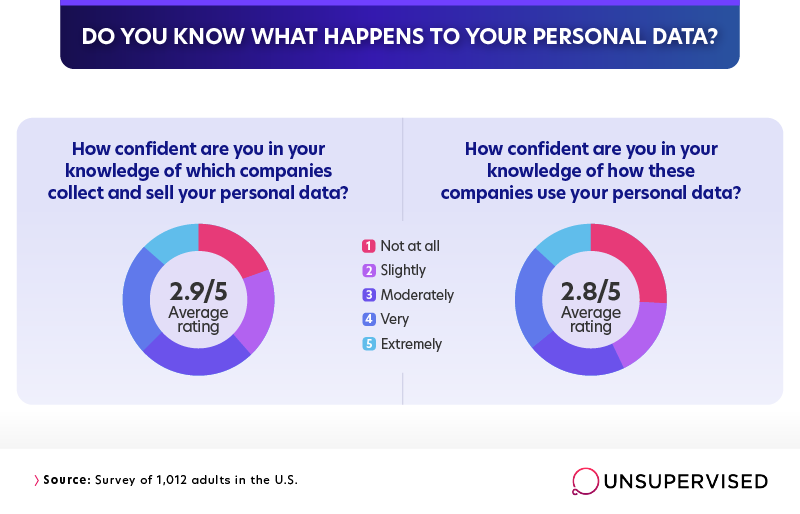
Older respondents tended to rate themselves as less confident than younger respondents. For example, Gen Xers rated themselves about 0.3 points lower, on average, than millennials on both questions.
Low levels of self-confidence regarding data knowledge speak to a broad sense that what’s happening to our personal information is obscured, hidden, or difficult to understand. According to our survey, more than 1 in 4 felt they had absolutely no confidence in their knowledge of how personal information is used once it’s been collected. Only about half as many reported extreme confidence.
In 2019, a report from PEW Research Center found that more than 6 in 10 Americans believe that it’s impossible to go through daily life without companies collecting their personal data. When combined with our results, this statistic suggests that the majority of Americans live with the knowledge that they’re trading their personal information for access to free online services, such as social media, but don’t feel confident in their ability to understand what happens to it.
Overconfidence is common
When asked to compare themselves to the average person, we found that survey respondents tended to be much more confident in their data knowledge. A strong majority (69%) viewed themselves as above-average in this respect.
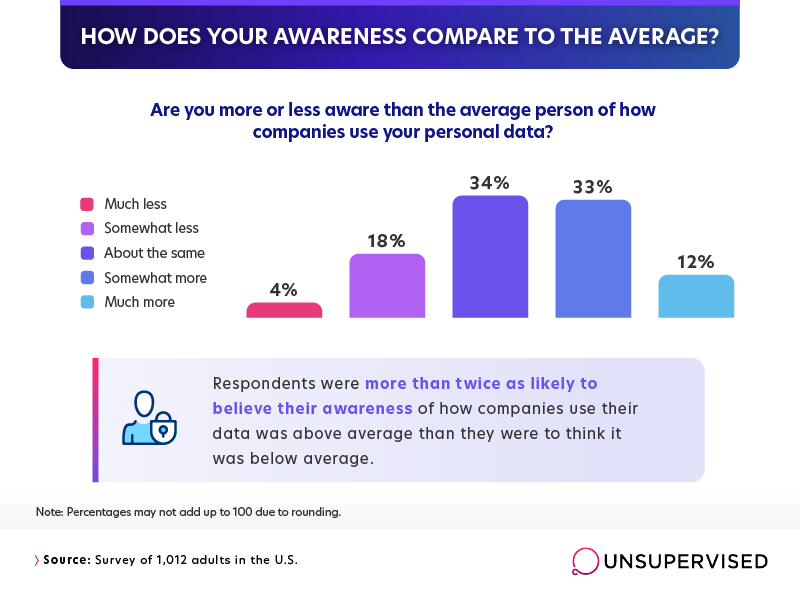
People also tended to rate themselves as above average when it came to using advanced privacy settings for apps and websites. Forty-nine percent said they were more attentive to such things than the average person, compared to only 19% who believed themselves less attentive.
Data as currency is an uncomfortable norm
At some point or other, we’ve all been guilty of skipping over a user agreement or privacy policy and just clicking “Accept.” Although this course of action is hardly recommended, we found that it’s pretty common: More than half (56%) of respondents admitted that they accept online terms and conditions without reading them most or all of the time. And although only a slim majority of respondents were willing to admit to blindly accepting online agreements, previous research on the subject suggests that the actual number may be upwards of 90%.
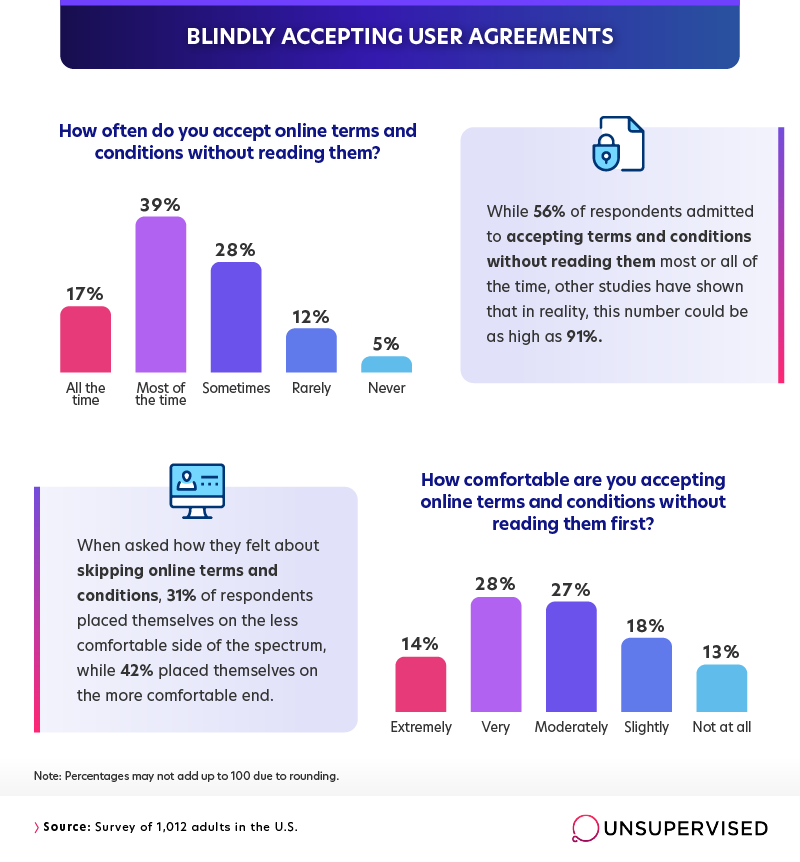
For the most part, people were reasonably comfortable with blindly accepting online agreements. It’s unclear whether this shows broad trust in a system that presumably prevents companies from putting predatory language in these agreements or belies a common assumption that even if one were to read the documents, shady language would be hard to identify.
Regardless, consumers largely understood that forking over personal information is the price of entry for many modern online services. On average, respondents believed that their personal information is collected and sold by about 71% of the online services they use.
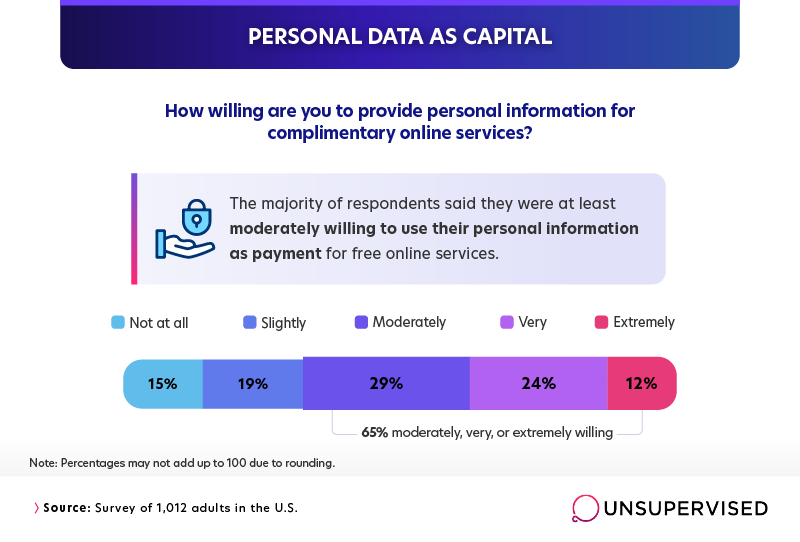
Although the majority of people were at least moderately willing to use their personal information as payment for free online services (65%), we also found that a similar percentage (64%) felt at least somewhat uncomfortable with the arrangement. Through these results, we uncovered a picture of an American public that has largely resigned itself to a situation it’s uncomfortable with.
The majority of Americans also understand that ads are the largest source of revenue for most social media platforms. For companies that raise large chunks of their revenue from personalized digital advertising, public acceptance of data-as-capital is crucial to success. A good window into this economy is a metric called the Average Revenue per User (ARPU), used to quantify the success of a software product by the amount of money raised per person who uses the service. When a company or product’s revenue is largely generated by the customer surrendering personal information in exchange for use of a “free” service, the ARPU becomes roughly equivalent to the real price “paid” for the service by the consumer.
For example, Facebook, which generates over 95% of its revenue through advertising, achieved a worldwide ARPU of $32.03 in 2020—meaning that the average user traded their personal information for the ability to use Facebook at a value of around $30.
Who should be in charge of data protection?
For those of us who regularly use online services that collect our personal information, data security becomes a crucial concern. Who should be most responsible for protecting this information from misuse?
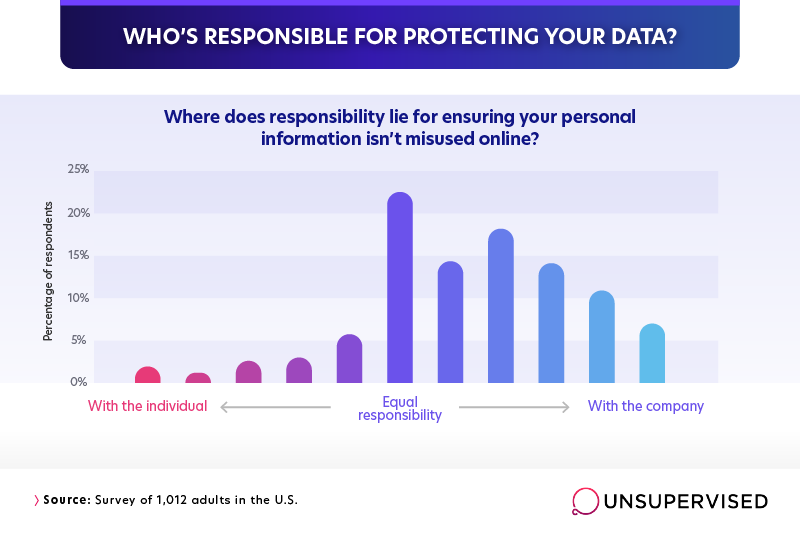
A significant majority of respondents agreed that companies are more responsible than individuals for ensuring that personal data is not misused (63%). However, a sizable portion (roughly 23%) asserted that responsibility should be equally shared between companies and individuals. Recent reports have reflected these conflicting feelings about the share of blame for data privacy breaches: Some consumers blame themselves for placing trust in a system that fails fairly regularly, while still acknowledging the role that companies need to play in protecting the data they profit from.
Consumers are eager to learn more about data
Earlier in this report, we saw that the public’s self-confidence in terms of data economy knowledge was mediocre at best. Does this lack of confidence translate to a lack of interest, or do people generally want to improve?
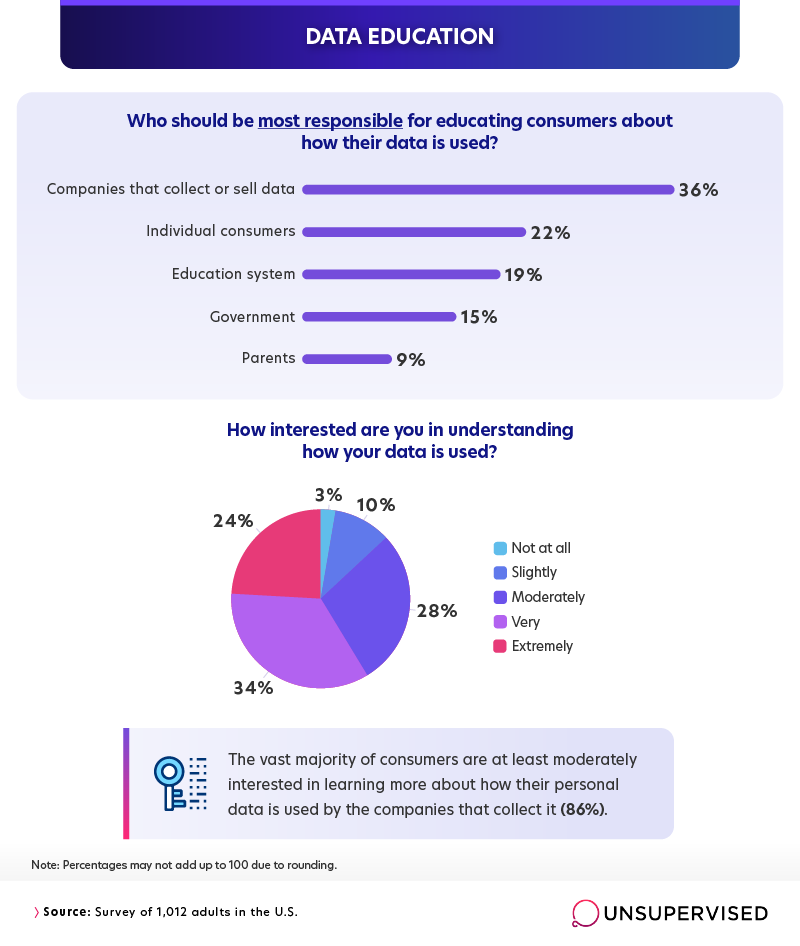
Overwhelmingly, we found that most consumers are interested in learning more about how their data is used by the companies that collect it. Only 3% of respondents indicated a complete lack of interest in further education.
It’s interesting to note that although the public seems generally uncomfortable with companies collecting personal data, many of us also believe that these same companies should be the ones responsible for educating us about the way consumer data is used. Companies profiting from data trafficking was the most common answer to the question “Who should be most responsible for educating consumers about how their data is used,” followed by individual consumers, then the education system.
Looking forward to better knowledge
Consumers are conflicted. While many have accepted that the online service economy relies on selling personal information, most are also uncomfortable with the situation. Despite their misgivings, however, consumers continue to participate in trading their data for access to services.
That being said, the public is very interested in further education on data topics. People are hungry to know how they can improve their own agency, and what happens to the information they hand over to internet companies.
For businesses looking to level up their own confidence in data knowledge, solutions can sometimes be expensive. Unsupervised is a cost-effective way to transform obscure and complex business data into key insights without hiring an entire analytics department.
Methodology and limitations
Data used in this analysis came from a survey of 1,012 American adults on the Amazon Mechanical Turk platform. To ensure the integrity of survey respondents, all respondents were required to pass an attention-check question. Top-level survey results have a 3% margin of error at a 95% confidence level.
Our sample included 555 men, 450 women, and seven respondents who reported another gender identity or declined to provide one. Fifty-eight percent of respondents were millennials, 25.5% were Gen Xers, 12% were baby boomers, and the remaining 4.5% were from other generations.
Limitations of this study include those commonly attributed to survey data, which may include telescoping, exaggeration, selective memory, selection bias, and recency bias. It should also be noted that the majority (57%) of respondents indicated that they believe their internet usage exceeds that of the average American. This exploratory project examines prevailing attitudes in the American public.
Fair use statement
Data competency is something everyone should strive for. If you’d like to share our findings, feel free to quote or distribute this report for any noncommercial purpose. Just give credit where it’s due by providing a link back to this page.


